What 100 developers on Claude Code actually costs in 2026, and what Hydrate does about it
Anthropic quietly revised their Claude Code cost estimates upward. Average developer: $13/day. 90th percentile: $30/day. For a 100-person engineering team that's $312,000 a year before you account for onboarding, churn, or model choice. Here's the full breakdown, and the benchmarked numbers behind what Hydrate saves.
The number that changed quietly
Business Insider reported this week that Anthropic revised their Claude Code documentation without announcement. The estimated average daily cost for a developer moved from $6 to $13. The 90th percentile (your power users, your senior architects, the people running long agentic loops) moved from $12 to $30 a day.
Anthropic's response was that there was no pricing change, only an update to reflect how usage had evolved as model capabilities grew. That is technically accurate. Claude Code now defaults to Opus 4.7 where it previously used Sonnet 3.7. Opus 4.7's tokeniser consumes around 35% more tokens for identical text. The million-token context window compounds costs across long sessions. None of this is a pricing decision. It is just what happens when the model gets more capable and developers lean into it.
The result is the same either way. The bill went up.

The real cost of 100 developers
Let's build the actual number. A 100-person engineering team is a common planning unit for mid-to-large companies. Not all 100 will be power users. A reasonable split, based on how Anthropic's own distribution works:
| Segment | % of team | Daily cost | Monthly (20 days) | Annual |
|---|---|---|---|---|
| Light users | 30 developers | ~$6/day | $3,600 | $43,200 |
| Average users | 50 developers | $13/day | $13,000 | $156,000 |
| Power users (90th %ile) | 20 developers | $30/day | $12,000 | $144,000 |
| Total | 100 developers | $28,600/month | $343,200/year |
If you're on Anthropic's flat-rate Max plans ($100/month for 5x capacity, $200/month for 20x), your ceiling is lower but your floor is set regardless of usage. At $200/seat for 100 developers: $240,000 a year, paid whether the developers use it or not.
Either way you're looking at a six-figure annual line item for Claude Code alone, before you count GitHub Copilot, Cursor, or any other tooling already in your stack.
And that number doesn't include the invisible cost: context.
The invisible tax: re-establishing context
Every Claude Code session starts cold. The model has no memory of what your codebase does, what decisions were made last week, what the architectural constraints are, or what the previous developer on this ticket already tried. Your developer has to re-establish all of that through prompts, which means tokens, at the start of every session.
This is not a minor inefficiency. It is structural. And it compounds.
In a team of 100 developers, the same context is being re-established hundreds of times a week. The architectural decision that was explained to Claude on Monday is explained again on Tuesday by a different developer working on a related ticket. The constraint buried in session 3 that Claude never reconciled with the feature it designed in session 30. That is not a one-off failure mode. That is every developer, every session, every day.
Hydrate addresses this directly. Facts captured in one session are injected into the next. A developer who established a constraint once doesn't have to establish it again. The team that captured an architectural decision in shared memory doesn't have to re-explain it to every new Claude session that touches the same area.
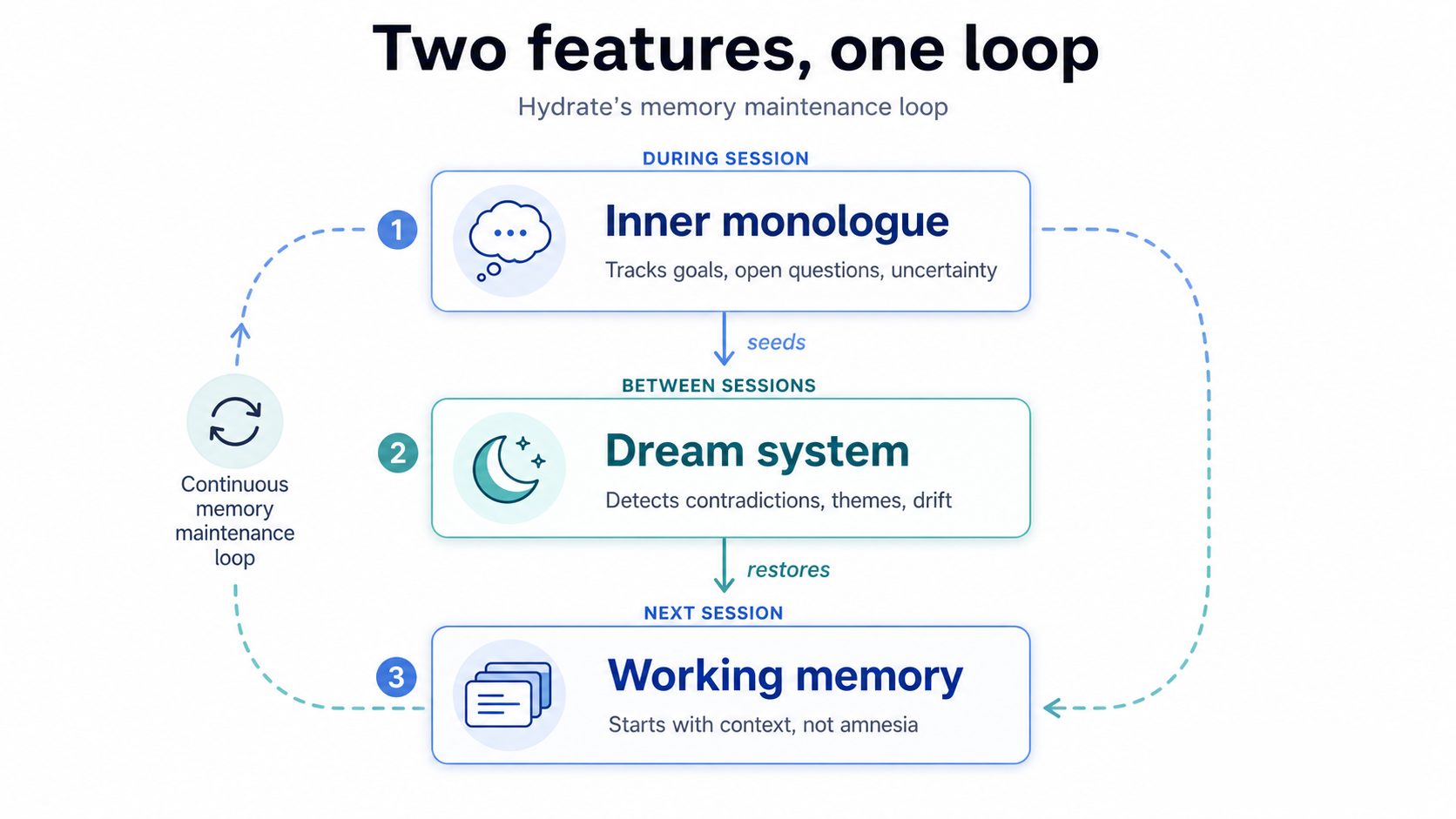
What the benchmarks actually show
We don't publish estimates. We publish benchmarks. Here is what we measured.
We ran 18 sequential Claude Code sessions across three simulated developers (Alice, Bob, and Carol) all working on the same codebase. Round 1 sessions were fresh starts. Round 2 sessions used Hydrate's shared team memory: each developer received the accumulated context from their teammates' prior sessions injected at the start of their own.
| Metric | Round 1 (no memory) | Round 2 (team memory) | Change |
|---|---|---|---|
| Cost per session | baseline | −51% | 51% cheaper |
| Turns per session | baseline | −44% | 44% fewer turns |
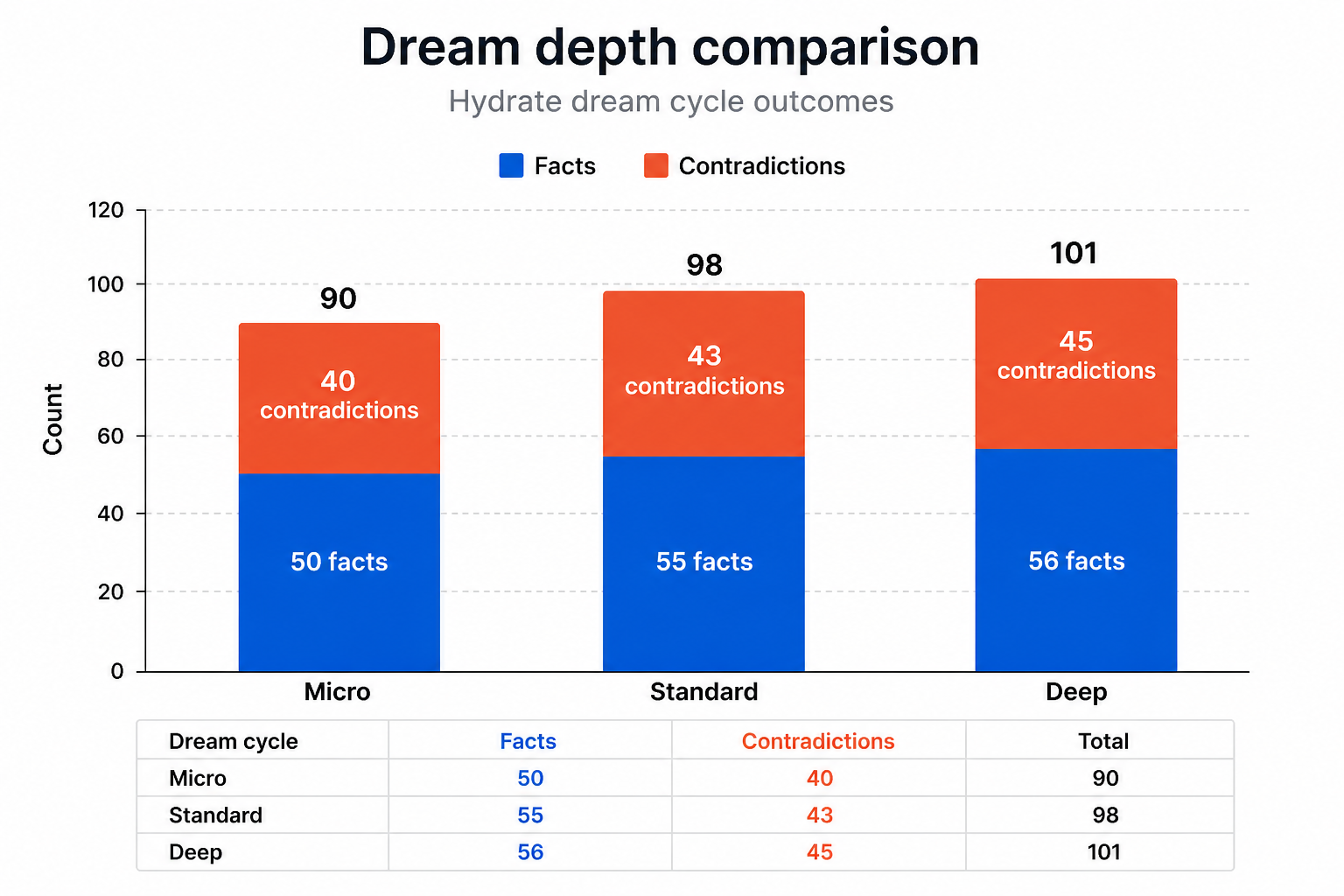
| Carol's lint task | 12 turns | 3 turns | 75% fewer turns |
| Overall cost reduction | across all 18 sessions | 39% | |
The 51% figure for Round 2 is the one that matters most for a team at scale. It is not an average flattened across fresh starts and warmed-up sessions. It is what happens specifically when a developer builds on their teammates' context, which is what every developer on a shared codebase does, every day.
Applied to our 100-developer model: a 39% reduction on $343,200 saves $133,800 a year. As team memory matures and more sessions are Round 2 equivalent, that moves towards 51%: $175,000 saved annually. On the same spend. Without changing a single tool or workflow.
Onboarding: the hidden multiplier
A new developer joining a team running Claude Code without Hydrate starts from scratch on two fronts simultaneously. They don't know the codebase, and Claude doesn't either. Every "how does this system work" question burns tokens. Every architectural constraint has to be explained from first principles. Every convention has to be rediscovered.
We demonstrated the alternative precisely. In our tier verification test, Alice scaffolded a complete Go REST API (authentication, rate limiting, pagination, RFC 7807 errors) from 13 injected facts and an empty directory. No source files. No prior Claude Code sessions. One prompt. The API was correct.
Bob joined the same project on a separate machine with no source files. From injected context alone, he listed every architectural decision, every convention, every constraint without reading a single file. His closing line: "this is all from injected hook context."
For a team hiring at even a moderate pace (say, 15 new developers a year) the onboarding token burn is substantial. Industry estimates put the productivity ramp for a new developer joining a complex codebase at four to eight weeks. During that period, Claude Code sessions are disproportionately expensive: lots of exploratory queries, lots of context re-establishment, lots of turns that would be unnecessary if the developer already knew the conventions.
Hydrate collapses that ramp. The new developer receives what the team has already captured: conventions, constraints, decisions, preferences, all injected from day one. The expensive exploration phase is shortened. The token bill reflects it.

Developer churn: the knowledge drain
Tech industry churn rates run at 15 to 25% annually. For a 100-person team, that is 15 to 25 developers leaving in a year, taking with them everything they knew about the codebase, the decisions they made, the constraints they discovered, the shortcuts they learned.
Without Hydrate, that knowledge evaporates. The new hire starts the same expensive exploration phase. The constraints the departing developer had already captured in Claude sessions are gone. Not in the codebase, not in the documentation, not anywhere a new session can reach them.
With Hydrate, every session the departing developer ran has been progressively captured. Architectural decisions, preferences, constraints, conventions: they accumulate in the shared team store. When the new hire starts, they inherit what their predecessor learned. Not as a document someone had to write, but as injected context that fires automatically on their first prompt.
| Scenario | Without Hydrate | With Hydrate |
|---|---|---|
| Developer leaves after 18 months | Knowledge gone; new hire starts cold | ~18 months of captured context inherited by successor |
| New hire onboarding (token cost) | 4 to 8 weeks of high-burn exploratory sessions | Team memory injected from day one; ramp compressed |
| Architectural decision made 6 months ago | Has to be re-explained or rediscovered | In the fact store; injected when relevant |
| Same mistake made twice | Common. No cross-session memory | Dream system surfaces contradictions before they become responses |

At 20% churn (20 leavers a year) the compounded saving from shorter onboarding ramps, lower exploratory token burn, and preserved institutional knowledge is substantial. It does not show up neatly in a monthly Claude Code invoice, but it is real, it is measurable, and it grows with team size.
Mixed toolchains: Copilot, Claude Code, Cursor, Mistral
Most teams are not running a single AI tool. They are running several: GitHub Copilot for autocomplete, Claude Code for architectural work, Cursor for IDE-integrated sessions, and increasingly local or open models for tasks where cloud billing is hard to justify.
The problem this creates is fragmentation. A developer who establishes project context in a Claude Code session gets none of that context when they switch to Cursor. A convention captured in a Copilot session is invisible to Claude. The memory lives in the tool, not with the developer.
Hydrate is tool-agnostic by design. It works via two mechanisms: hooks (for Claude Code) and MCP (for any agent that speaks the protocol: Cursor, Gemini CLI, any MCP-capable tool). The same fact store, the same injected context, regardless of which tool is open.
We demonstrated this directly. In our cross-vendor test, Alice and Bob built a Go API across Claude Code sessions. Carol joined on Mistral Vibe (a completely different vendor, different model, different tool) and started with their full project memory on her first tool call. She added a logging convention. Alice picked it up in her next Claude Code session and extended it. Full round trip: Claude Code to Mistral Vibe back to Claude Code. One shared fact store.
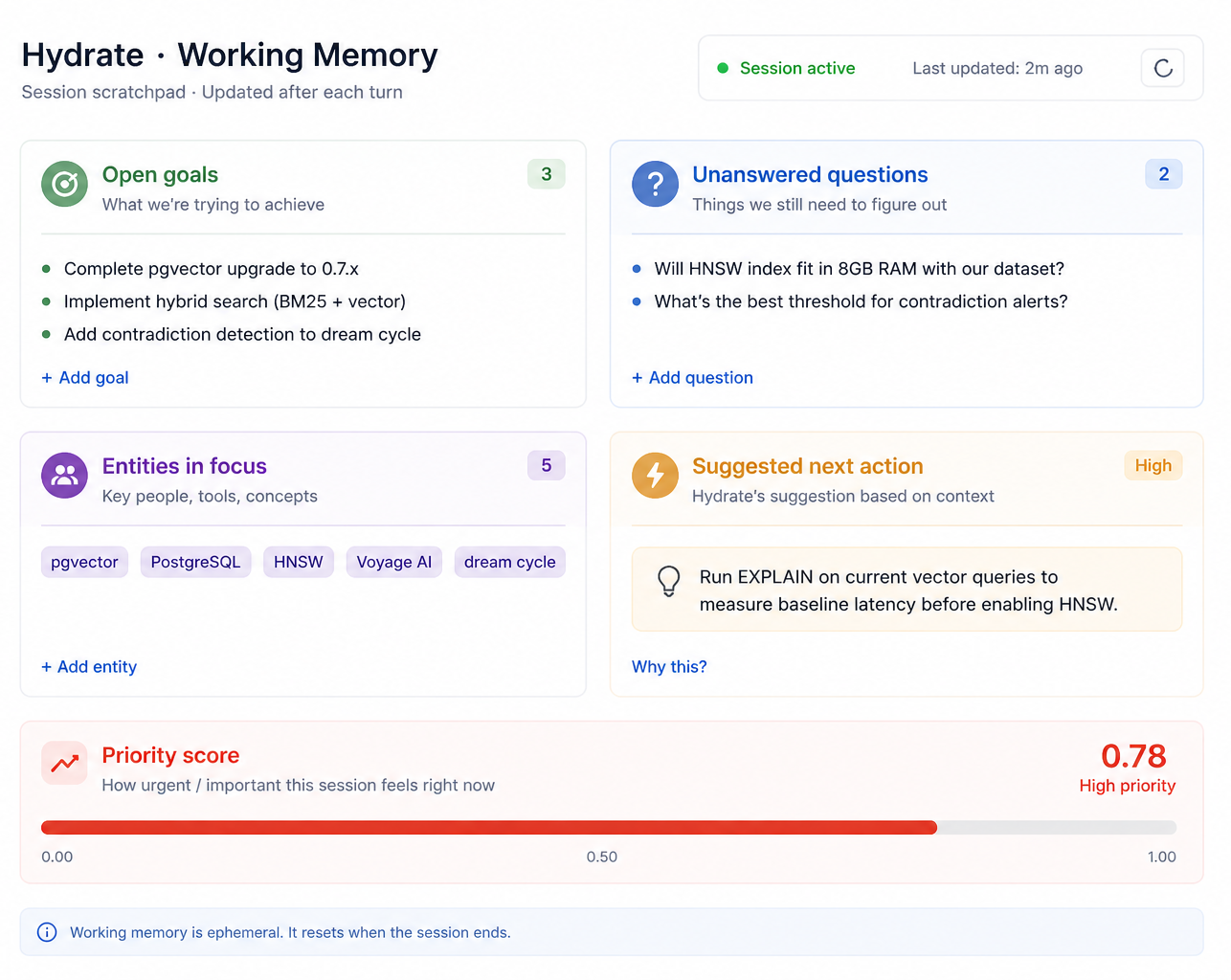
For a 100-developer team already paying for Copilot ($19/seat = $1,900/month) alongside Claude Code, Hydrate ensures that spend is not siloed. The context captured in Claude Code sessions is available in Copilot sessions. The convention a developer added during a Cursor session is there when they open Claude Code the next morning. The investment in one tool's context compounds across all of them.
The model substitution play
The Business Insider article centres on cost, but the underlying driver is model choice. Claude Code defaulting to Opus 4.7 means every session is priced at Opus 4.7 rates. Opus is the right model for some tasks: complex architectural reasoning, multi-file refactoring, synthesising across a large codebase. It is the wrong model for many others.
Memory changes this equation.
When context is injected rather than rediscovered, the model doing the work needs less raw capability to get to a correct answer. A well-contextualised Haiku 4.5 session can handle tasks that would require Sonnet or Opus when starting cold, because the hard work of establishing context has already been done outside the model call.
We benchmarked this in our cost efficiency study. Our Hybrid cell (memory-assisted routing that sends queries to the most cost-effective capable model) ran at $0.20 per session. That is 12% of the cost of raw Opus. We ran it across twelve benchmark scenarios, five realistic use cases, and it shipped 7 out of 7 correct results. Not by using a worse model. By using the right model for each task, with the context it needed to succeed.
| Approach | Cost per session | Quality | Notes |
|---|---|---|---|
| Raw Opus (no memory) | ~$1.67 | 7/7 | Benchmark baseline |
| Sonnet (no memory) | ~$0.50 | 6/7 | One failure on complex synthesis |
| Hybrid (memory-assisted routing) | $0.20 | 7/7 | 12% of Opus cost, identical results |
A 100-developer team running Opus-default Claude Code at $28,600/month that can shift even 30% of queries to appropriately-routed cheaper models saves in the range of $8,000 to $12,000 a month. The capability stays. The invoice doesn't.
Putting it together: 100 developers, one year
Here is the full picture for a 100-person engineering team moving from unassisted Claude Code to Claude Code with Hydrate.
| Cost category | Without Hydrate | With Hydrate | Annual saving |
|---|---|---|---|
| Claude Code usage (100 devs) | $343,200 | $208,800 (−39%) | $134,400 |
| Onboarding token burn (15 new hires/yr) | High. 4 to 8 wk ramp per hire | Compressed. Injected context from day 1 | Significant (unquantified) |
| Developer churn knowledge loss (20% rate) | Knowledge evaporates on exit | Captured progressively; inherited by successor | Preserved |
| Cross-tool context loss (Copilot/Cursor/Mistral) | Context siloed per tool | One fact store, all tools via MCP/hooks | Compounding |
| Model over-spend (Opus for tasks suited to Haiku) | Full Opus rate on all queries | Hybrid routing to cheapest capable model | Up to $100K additional |
| Total documented saving | $134K to $234K/year | ||
The $134,000 figure is conservative: it applies only the 39% benchmark reduction to the baseline Claude Code spend. The $234,000 upper end adds the model substitution saving. The onboarding, churn, and cross-tool figures are not in this number. They are real, they are measurable in your own environment, and they are not small.

What this requires from you
Hydrate installs as a single binary. The hooks wire into Claude Code's
~/.claude/settings.json automatically. The MCP server makes the same memory
available to any other tool in your stack. There is no infrastructure to run, no model to
host, no API to call. It runs locally.
For a team of 100, the team tier adds a shared git-based fact store: facts captured by any developer are available to every developer, synced through a remote you already control. Alice's context is Carol's context. The architectural decision your most experienced developer captured last Tuesday is in the injected context for the new hire starting this Monday.
Anthropic will keep improving Claude Code. The models will get more capable. The costs will continue to reflect that. The session-cold memory problem is not going away; it is structural to how LLMs work. Hydrate is not a workaround for a temporary pricing anomaly. It is the layer that makes the tool sustainable at scale.
The Business Insider article framed this as a cost story. It is also a capability story. A 100-developer team that compounds context across sessions, across developers, and across tools is not just spending less. It is getting more done with what it already has.
Ready to run your own numbers?
Hydrate is free to install. The benchmark methodology (all 18 sessions, all three developers, all five cost scenarios) is published on this blog.