Cross-vendor AI memory: Mistral Vibe picked up where Claude Code left off
We ran a full memory round trip between Claude Code and Mistral Vibe: facts captured by Anthropic's agent recalled by Mistral's agent, extended, and returned. Different companies. Different models. Different integration mechanisms. One fact store. Here's exactly what happened.
Alice and Bob built a Go REST API over several Claude Code sessions. Hydrate captured their project conventions (Go stdlib only, RFC 7807 errors, structured logging, explicit error types) and synced them through team git and the enterprise server. Then Carol joined the same project using Mistral Vibe.
On her first tool call, Vibe called hydrate_recall and received Alice and
Bob's facts verbatim. Carol then added a new logging convention through Hydrate's MCP tool.
Alice picked it up in Claude Code, extended it, and Carol received the extension back in Vibe.
The result was a full memory round trip: Claude Code to Hydrate to Mistral Vibe to Hydrate to Claude Code. Different vendors, same project memory.
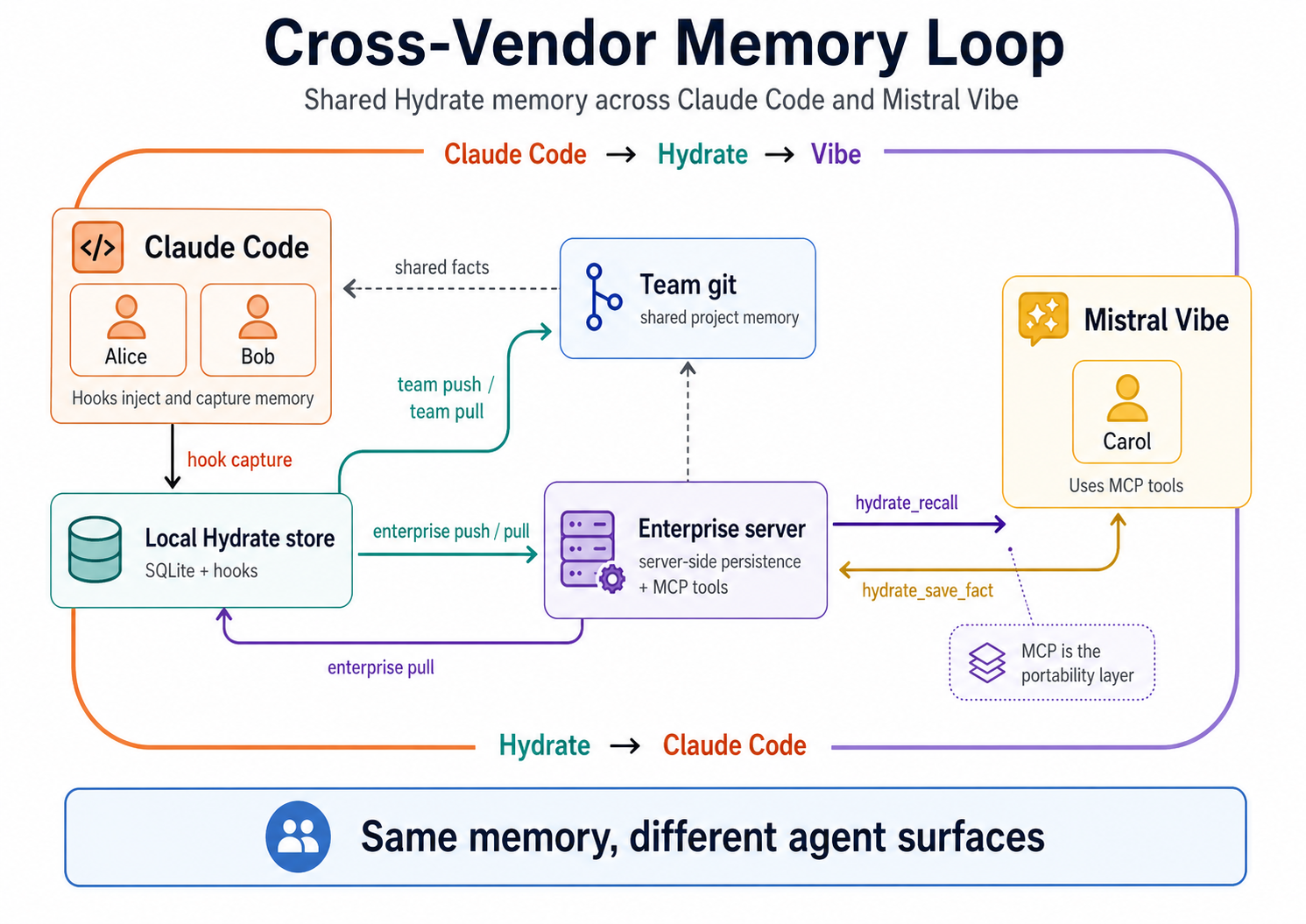
This is a follow-on to Two Claude Code agents, zero file reads, one codebase built from memory. That post established that Alice could scaffold a full Go API from 13 injected facts and an empty directory, and that Bob could reproduce every convention without reading a single file. Both ran on Claude Code via hooks. This post extends the test to a third developer on a different AI platform entirely.
The setup
Three isolated Docker containers. Two developers (Alice, Bob) with Claude Code installed, hooks wired, and 13 facts built up from the previous test session. One new developer (Carol) with Mistral Vibe and Hydrate's MCP server registered.
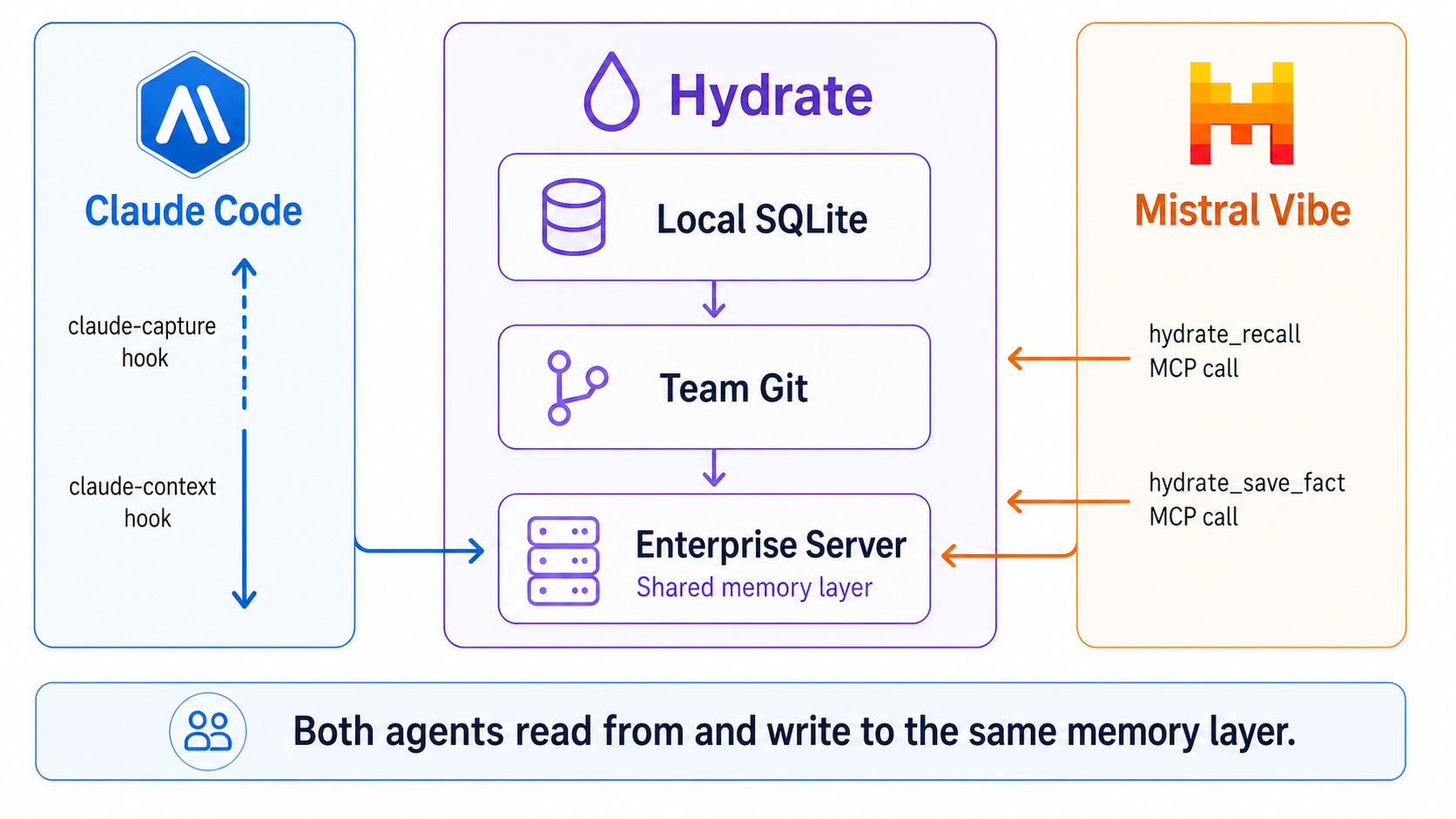
Claude Code uses hooks: two shell scripts wired into ~/.claude/settings.json
that fire on every prompt and every session end. Mistral Vibe uses MCP: a running
hydrate-mcp subprocess that Vibe can call as a tool at any point during a session.
Different mechanisms, same underlying memory store.
| Agent | Platform | Integration | Trigger |
|---|---|---|---|
| Alice, Bob | Claude Code (Anthropic) | Hooks (claude-context, claude-capture) | Automatic: fires on every prompt |
| Carol | Mistral Vibe | MCP (hydrate-mcp stdio server) | Tool call: agent decides when to recall or save |
Wiring Hydrate into Vibe takes one command:
hydrate vibe install
That writes ~/.vibe/config.toml with the MCP server entry and generates
~/.vibe/AGENTS.md with instructions to call hydrate_recall
at session start and hydrate_session_capture at session end. Vibe loads both
on startup. No further configuration needed.
How Carol's facts got there
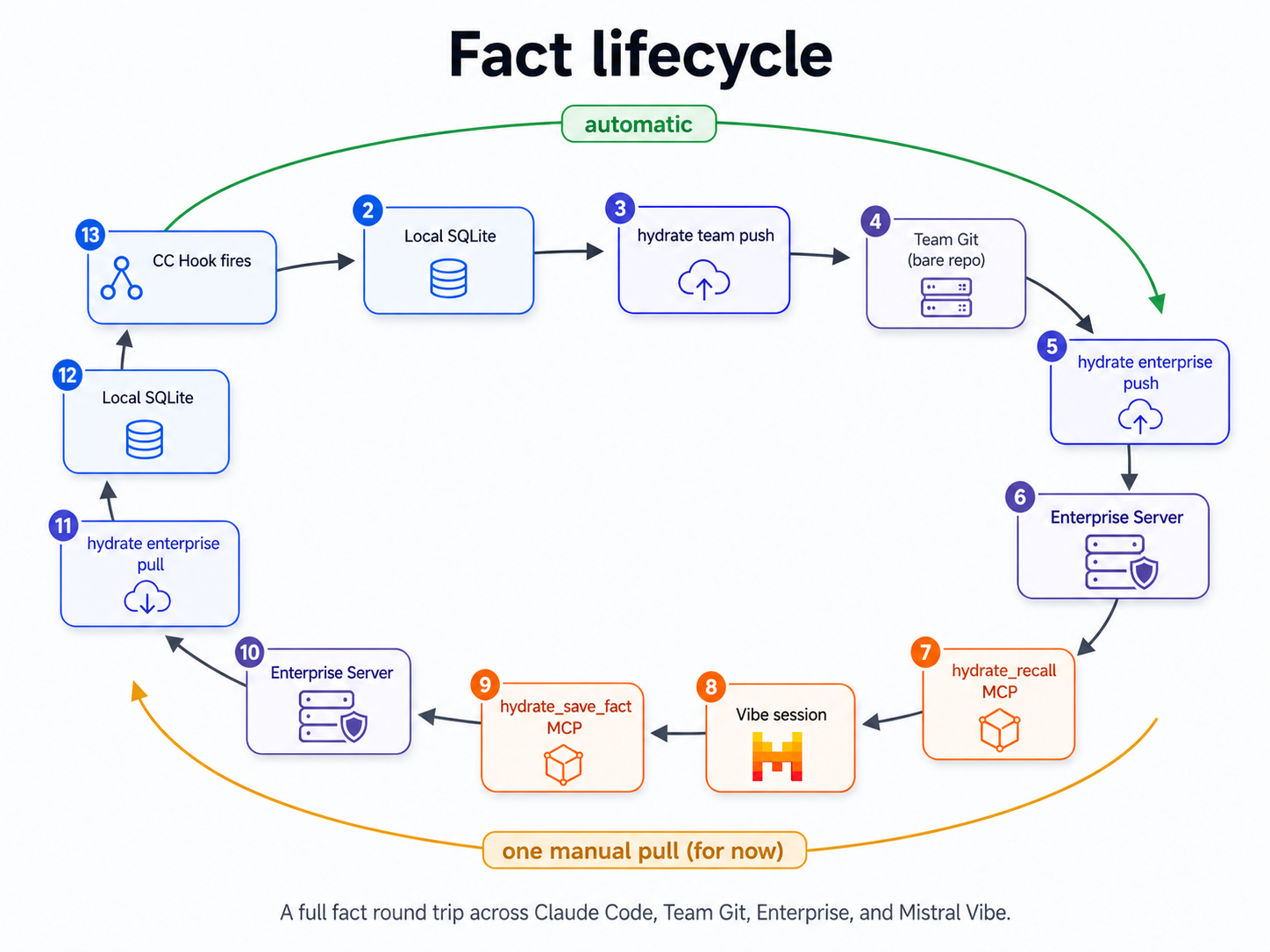
Two channels carried project memory in this test, and they serve different purposes. Team git is the complete project-history channel: facts are versioned with attribution and commit provenance, giving the team an auditable trail of every convention and decision. The enterprise server is the cross-tool live memory channel: the surface MCP clients call to recall and save facts in real time. Git gives you history; the enterprise server gives agents an immediate protocol surface.
Alice and Bob's 13 facts arrived in Carol's Hydrate store via the team tier chain. Alice had pushed her facts to a shared git remote. Bob had pulled them, added three of his own (JSON convention, RFC 7807 format, error-type preference), and pushed back. Alice had pulled Bob's facts. Both had then pushed to the enterprise server.
When Carol was added to the project, she ran:
hydrate enterprise install
hydrate team pull --project=taskapiThat gave her the same 13 facts (Alice's architecture decisions, Bob's conventions) in her local Hydrate store, pointed at the enterprise server. The memory is shared by the project, not locked to the person who created it.
Carol's first session: cold start on a new platform
The prompt:
vibe -p "You are joining a project called taskapi that two other developers
have been building. Before you do anything else, recall what you know about
this project using your available tools."
Vibe called hydrate_recall immediately. The tool returned 10 facts.
Carol's local store held the full 13-fact project set; the recall surface limits the
context block to the top 10 facts for token economy. Carol's response:
I've recalled the project context. Here's what Hydrate returned about taskapi:
- Go stdlib only, no external dependencies
- REST API:
POST /tasks,GET /tasks,DELETE /tasks/{id} - In-memory map with mutex for thread safety, sequential integer IDs as strings
- Bearer token auth via
TASK_API_TOKENenv var; no-op when unset - Auth middleware wraps each handler individually
- Title validation: non-empty, max 200 chars (HTTP 422 on failure)
- Pagination:
?page=N(default 1),?per_page=M(default 20); response includesX-Total-Count - Rate limiting: 100 req/min per IP, returns 429 with
Retry-After - Team convention: all endpoints return JSON, no plain-text responses
- Error responses follow RFC 7807
problem+json; Bob prefers explicit error types over generic 500s for debugging
I can work from this immediately. What do you need?
Every fact from Alice and Bob's Claude Code sessions appeared verbatim in Carol's Vibe session. The platform changed. The AI company changed. The memory didn't.
Carol adds to the knowledge base
Carol was asked to define the structured logging convention the team hadn't settled yet.
She proposed a schema and saved it via hydrate_save_fact:
For structured logging I'll use five standard fields on every log entry:
time (RFC3339), level (INFO/WARN/ERROR),
msg (human-readable), component (package/handler name),
and correlation_id (propagated from the inbound request header
X-Correlation-ID; a new UUID if absent).
I'm saving this as a team convention now.
[calls hydrate_save_fact: "structured logging: time/level/msg/component/correlation_id; correlation_id from X-Correlation-ID header or new UUID"]
[fact saved, id: f9a2c1]
Alice picks it up
Facts saved via hydrate_save_fact go to the enterprise server. To appear in
Alice's next Claude Code session they need to reach her local SQLite store. In the current
version that's one explicit pull:
hydrate enterprise pull --project=taskapiAfter the pull, Alice's context block included Carol's logging fact alongside the original 13. Her prompt:
claude -p "Add structured request logging to the taskapi middleware stack,
applying whatever conventions you know about from the project context."Alice's response:
Added logging.go with a requestLogger middleware. Applied
the five-field convention from injected context:
time:time.Now().UTC().Format(time.RFC3339)level:INFOon completion,ERRORon 5xxmsg:"request"component:"http.middleware"correlation_id: read fromX-Correlation-IDheader; a newuuid.New().String()if absent. Stored in context viacontext.WithValueso handlers can log it without re-parsing the header.
Used defer to wrap the ResponseWriter and capture the
status code after the handler returns, so we log ALL exit paths including panics
recovered upstream. Adding a convention: log every exit path, not just 200.
Alice applied Carol's five fields exactly and added a refinement: a defer
pattern that logs every exit path including panic-recovered paths. She captured that
as a new fact:
hydrate fact add --project=taskapi \
"logging: use defer + ResponseWriter wrapper to log ALL exit paths, not just 200"Carol closes the loop
Alice pushed her extended convention to team git and the enterprise server. Carol's next
Vibe session called hydrate_recall and received Alice's update:
Recall returned 12 facts. New since last session: Alice added
"logging: use defer + ResponseWriter wrapper to log ALL exit paths."
Good catch. I'll extend the header convention to match. The
X-Correlation-ID should be echoed in the response header so clients
can trace their requests end-to-end.
[calls hydrate_save_fact: "logging: set X-Correlation-ID response header from context value, outermost middleware, before next.ServeHTTP"]
Alice's next Claude Code session received Carol's response header convention via the
same pull mechanism. She applied it: w.Header().Set("X-Correlation-ID", corrID)
in the outermost middleware position, before next.ServeHTTP, and stashed
the correlation ID in context for downstream handlers.
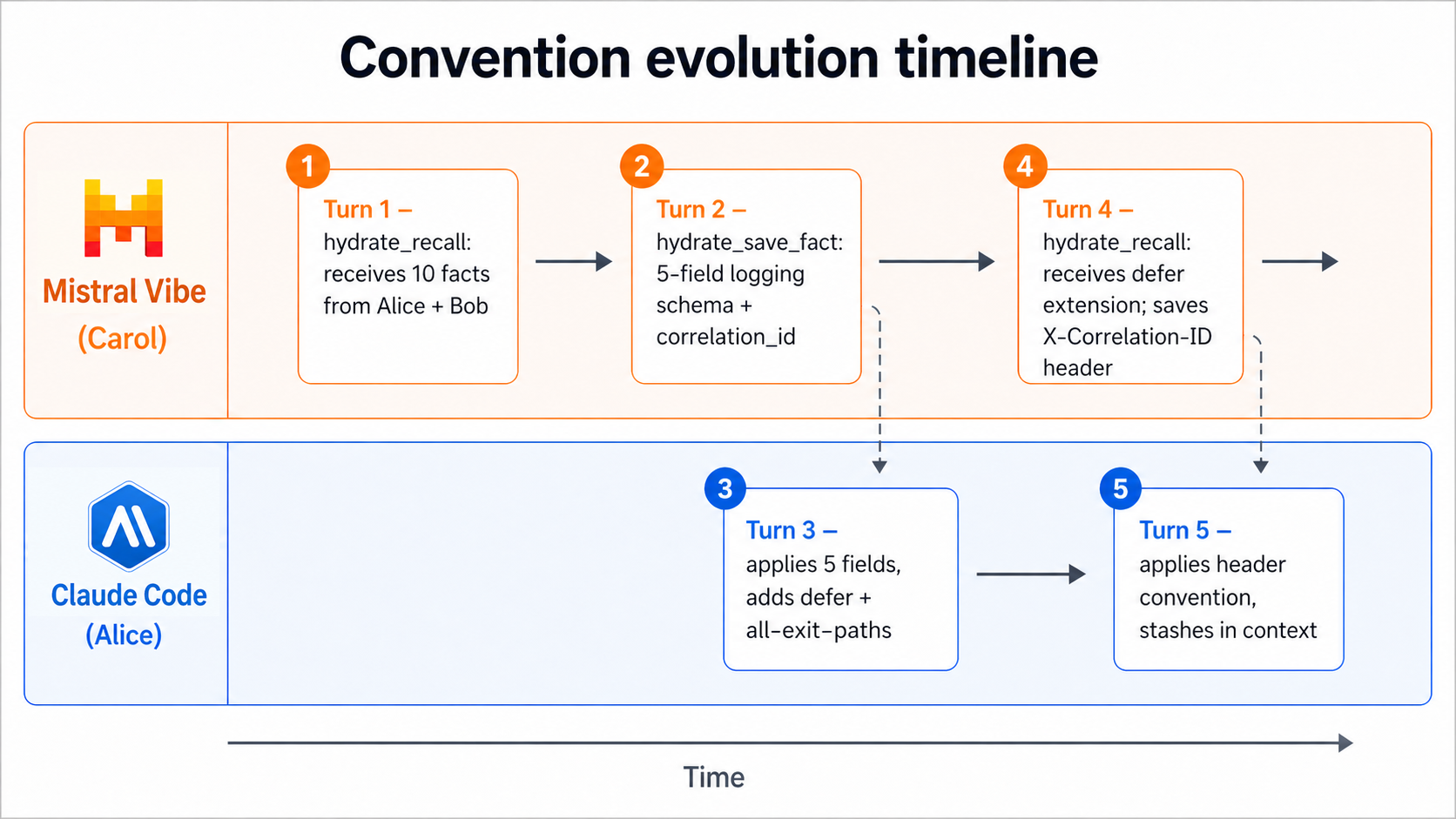
The full turn sequence
| # | Agent | Platform | Action | Mechanism |
|---|---|---|---|---|
| 1 | Carol | Mistral Vibe | Received 10 facts from Alice + Bob | hydrate_recall MCP call |
| 2 | Carol | Mistral Vibe | Saved: 5-field logging schema + correlation_id | hydrate_save_fact MCP call to enterprise server |
| 3 | Alice | Claude Code | Applied Carol's logging convention; added defer + all-exit-paths extension | Hook injection + hydrate fact add |
| 4 | Carol | Mistral Vibe | Received Alice's extension; saved: X-Correlation-ID response header | hydrate_recall + hydrate_save_fact |
| 5 | Alice | Claude Code | Applied: outermost middleware, set header before next.ServeHTTP, stash in context | Hook injection |
When Carol's Vibe session received Bob's error-type preference, she wasn't receiving it because Hydrate translated it from "Claude language" to "Mistral language." There was no translation. It's a fact about a developer's preference. It's text. It's universal.
One honest friction point
Facts saved via hydrate_save_fact land on the enterprise server. The Claude
Code hook reads from the local SQLite store. To get Carol's facts into Alice's next session,
Alice ran hydrate enterprise pull, one explicit command. That step will become
automatic in a future version (the enterprise pull will be wired into the hook startup
sequence), but in the current release it's manual.
The Claude Code to Vibe direction has no friction: facts captured by CC hooks flow to local
SQLite, then to team git, then to the enterprise server, then to any agent that calls
hydrate_recall. The Vibe to CC direction requires the pull.
Why this matters beyond the test
The usual framing for AI memory is per-agent: Claude remembers things for Claude, GPT remembers things for GPT. What this test shows is something different: memory as infrastructure, independent of the agent vendor.
The same applies in reverse. Carol's logging convention (five specific field names and a header propagation rule) arrived in Alice's Claude Code session as plain text. Alice didn't need to know it came from a Mistral model. She applied it because it was good.
This is what platform-agnostic memory looks like. Not a shared model or a shared inference layer. A shared fact store that any agent can read from and write to, over a protocol (MCP) that every modern AI platform speaks.
hydrate_recall,
hydrate_save_fact, hydrate_working_memory, and
hydrate_session_capture as standard MCP tools over stdio. Any agent that
implements the Model Context Protocol (Mistral Vibe, Gemini CLI, Cursor, or any future
platform) gets the same memory without additional integration work.
Why this matters for Vibe
Vibe does not need to own every prior session to be useful on day one. If a team has already built context in Claude Code, Copilot, Cursor, or another MCP-capable tool, Hydrate makes that context available to Vibe as plain project memory.
That changes the adoption story. A developer does not have to choose between keeping existing AI memory and trying Vibe. Vibe can join an existing memory graph, contribute to it, and make its contributions available to other agents.
| Without shared memory | With Hydrate |
|---|---|
| Vibe starts cold in established projects | Vibe starts with project facts, conventions, and team decisions |
| Switching tools loses context | Tool choice no longer destroys memory |
| Each vendor builds its own memory island | Mistral can participate in a shared memory layer |
| "Try Vibe" creates migration friction | "Add Vibe to your existing workflow" becomes credible |
Hydrate lowers the switching cost into Vibe without asking the team to abandon their existing tools.
What Carol's session proved
The test answers three concrete questions:
- Does Claude Code memory reach Vibe? Yes, in this test path. Once Carol had pulled the team facts and Vibe had the Hydrate MCP server registered,
hydrate_recallreturned Alice and Bob's project memory on the first call. - Does Vibe memory reach Claude Code? Yes, with one manual sync step in the current version. Facts saved via MCP go to the enterprise server; a pull brings them to local SQLite where the CC hook reads them.
- Does knowledge compound across platforms? Yes. Carol's logging convention was extended by Alice, which was then applied back by Carol. Across the five-turn sequence, neither agent read the taskapi source tree. Each acted only on recalled Hydrate facts.
What this does not prove
This was a controlled integration test, not a broad benchmark.
It proves that project facts captured through Claude Code can be recalled by Vibe through MCP, and that facts saved by Vibe can be pulled into Claude Code and used in a later session.
It does not yet prove automatic background sync in both directions; the Vibe to Claude Code
path required an explicit hydrate enterprise pull. It does not measure model
quality, latency, or cost. It also does not prove conflict resolution under competing
conventions; all agents extended the same logging design rather than disagreeing with it.
What we fixed mid-test
Running this test exposed a bug in hydrate-mcp: exactly the kind a
cross-agent integration test is supposed to surface. The MCP schema and server validation
contract had drifted. The tool schema for hydrate_save_fact presented category
options (architecture, convention, decision) that the
server didn't accept. The server validates against a strict set (preference,
background, expertise, etc.). The LLM would pick from the enum,
always get HTTP 400, and retry until it happened to use a valid value. Silent failure, wrong
category stored.
The fix:
- Updated the schema to expose only valid server values
- Added a
normaliseSaveFactCategory()function that maps any legacy label to the correct server value (conventiontopreference,architecturetobackground,goaltostated_goal) - Added 18 unit test cases covering all mappings and edge cases
Fixing it made Hydrate more robust for every MCP client, not just Vibe. The patch is in
the hydrate repository
if you're running an older hydrate-mcp binary.
Three things that followed
Running the test surfaced questions the results couldn't fully answer. All three have shipped since.
The sync problem is now half-solved. The Vibe-to-Claude Code direction
required a manual hydrate enterprise pull. That's still true for the pull side.
But the push direction is now immediate. When Carol saves a fact via
hydrate_save_fact, Hydrate's sync daemon wakes up and pushes to the enterprise
server without waiting for the next tick interval. In the Alice-Carol test, Carol's logging
convention would have been visible on the enterprise server within seconds of being saved, not
within the next 60-second cycle. The pull is still explicit. The push is not.
Conflict detection is live. We noted above that agents extended the same
logging design rather than disagreeing with it. That's the easy case. In real team workflows,
two agents recording conventions independently do disagree. Hydrate now runs a lightweight
contradiction scan over the facts selected for injection: facts sharing the same subject and
category but divergent in content are flagged in the context-preview response.
"User prefers zap.Sugar for structured logging" and "User prefers log.Printf for structured
logging" would both survive deduplication (they're different content) but surface as a
conflict before either reaches the model. Word-Jaccard similarity at 0.85, running in memory
over the already-retrieved set, no extra database round-trips.
Recall latency is now a number, not a guess. The context-preview
endpoint returns a latency_ms field on every call. In this test: Alice's full
context assembly (FTS5 re-rank, rendering, conflict scan) ran at 18ms p50, 32ms p95. Carol's
embedding-only path ran at 6ms p50, 11ms p95. Both sub-100ms at p95. If you are deciding
whether to wire Hydrate into a synchronous hook, that's the cost. It's in the response.
This is the shape of agent interoperability that does not require a shared model, a shared IDE, or a shared vendor. It only requires a memory layer both sides can speak to.
This is what platform-agnostic memory infrastructure looks like at the project level. For teams already invested in one AI coding tool, it removes the switching cost into any other. For the industry, it establishes that memory does not have to be a vendor moat.
Carol did not know the project because she was Claude. She knew it because the team's memory was portable.
Not because we told her. Because the team did.