What Hydrate does between sessions
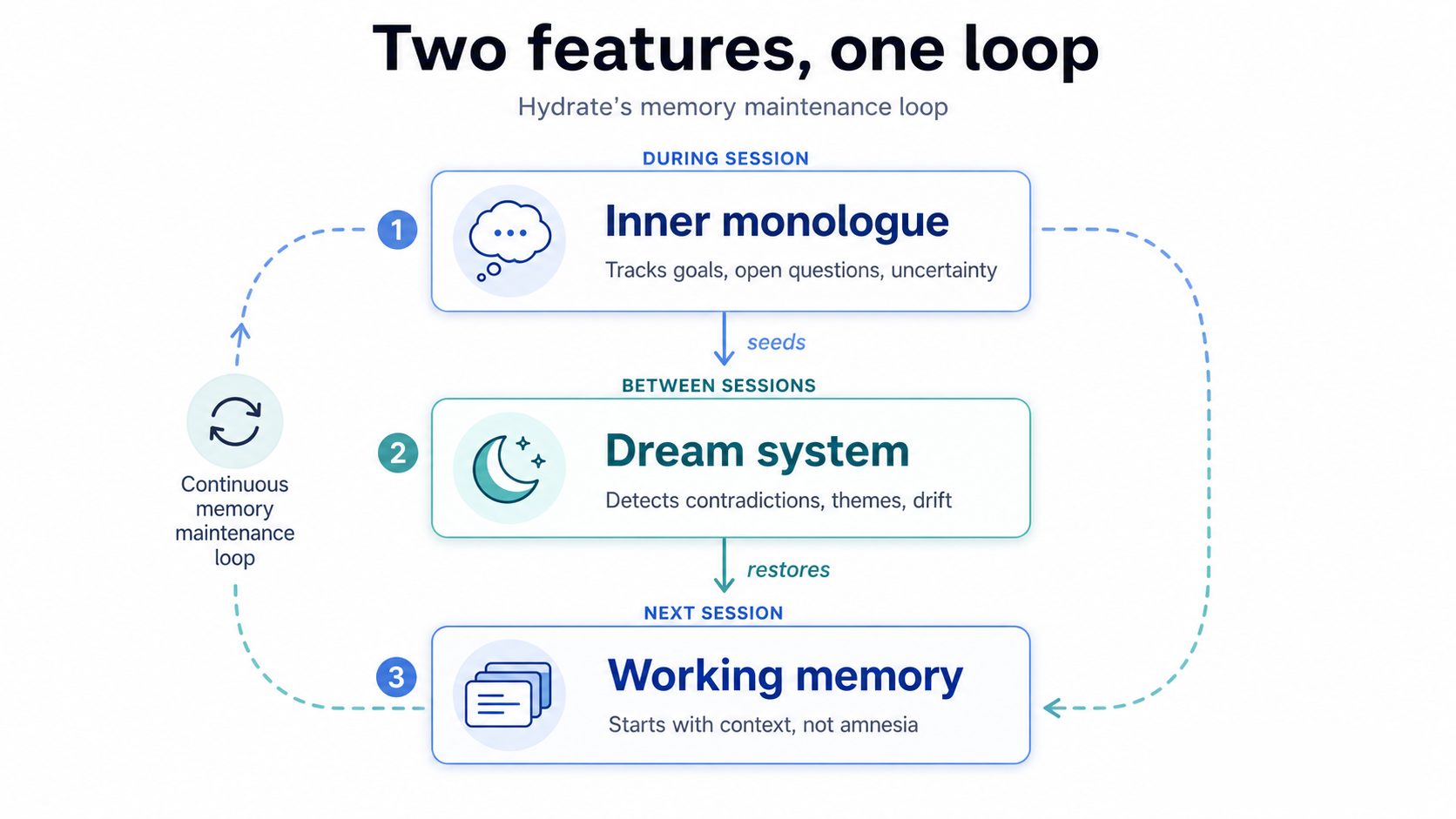
Two features, one loop. The dream system runs offline consolidation between sessions, scanning your fact store and detecting contradictions. The inner monologue runs during sessions, tracking goals and uncertainty. Here's what the test results show, and how to use both.

Capture is not enough
A few weeks ago I was working on a database migration with Claude. Early in the project I'd explained that we were pinned to pgvector 0.5 on the host, and that the cosine distance operator wasn't available in that version. Hydrate captured it. I could see the fact in the store. We moved on.
Four sessions later, Claude suggested adding cosine search using the operator I'd said wasn't available. It didn't hallucinate. It was being perfectly helpful, in isolation. But it had never reconciled the version constraint, buried in an early session, with the feature it was now designing. Both facts existed. They'd never been in the same context window at the same time.

That's the problem Hydrate was already halfway solving, and not fully solving.
A memory system that captures well but never consolidates is like a notebook you write in but never read back. Facts pile up. Some contradict each other. Neutral trivia competes equally with strongly-held decisions. And the AI that reads this notebook only ever reads a small slice of it per prompt, so contradictions that span sessions are invisible.

This is what the dream system and inner monologue are for.
What dreaming means here
Dreaming in Hydrate is not a metaphor for something fuzzy. It is a specific offline consolidation pass that runs between sessions, scans your fact store, detects contradictions, and produces a structured report.
The engine operates at three depths:
Micro scans the 50 most emotionally significant facts, using a strength floor of 0.3. It's designed for quick end-of-session consolidation, fast enough to trigger from the Stop hook without the user noticing any latency.
Standard scans up to 500 active facts with a strength floor of 0.1. This is the full active corpus, the equivalent of a thorough review.
Deep scans up to 5,000 facts with no strength floor. It reaches facts that have faded, preferences from months ago, decisions that were superseded. It's the mode that surfaces contradictions standard would miss.
| Mode | When to run | What it looks for | Best for |
|---|---|---|---|
micro | End of every session | High-strength contradictions (top 50 facts) | Fast automatic hygiene |
standard | Manual review | Active fact-store drift (up to 500 facts) | Weekly maintenance |
deep | Periodically | Faded or old contradictions (up to 5,000 facts) | Major project phase changes |
The output of any cycle is a dream report: a clarity marker, a tone, a shape, a list of
themes, and a contradiction count. Reports are transient. They expire after 72 hours, then
fade through [FUZZY] to [VAGUE] to gone. They're designed to be
glanced at and acted on, not archived.

Dream report
────────────────────────────────
Clarity: [CLEAR]
Tone: conflicted
Shape: architectural drift
Themes:
- pgvector version constraints
- search implementation assumptions
- old decisions resurfacing as new suggestions
Contradictions: 3
Expires: 72 hoursThe results, concretely
The point is not that every contradiction is dangerous. The point is that unattended contradictions become context debt. They sit quietly until the assistant retrieves one half of the story and acts as if it is still true.
We ran these three cycle types against a real fact store in a Docker test container. Here's what came back.
With 47 baseline facts in the store, all three cycle types returned identical results: 47 inputs considered, 37 contradictions. Which is itself a finding worth sitting with. Thirty-seven contradictions in a single developer's fact store. Facts that the system had never seen together in one context window, and had therefore never flagged.
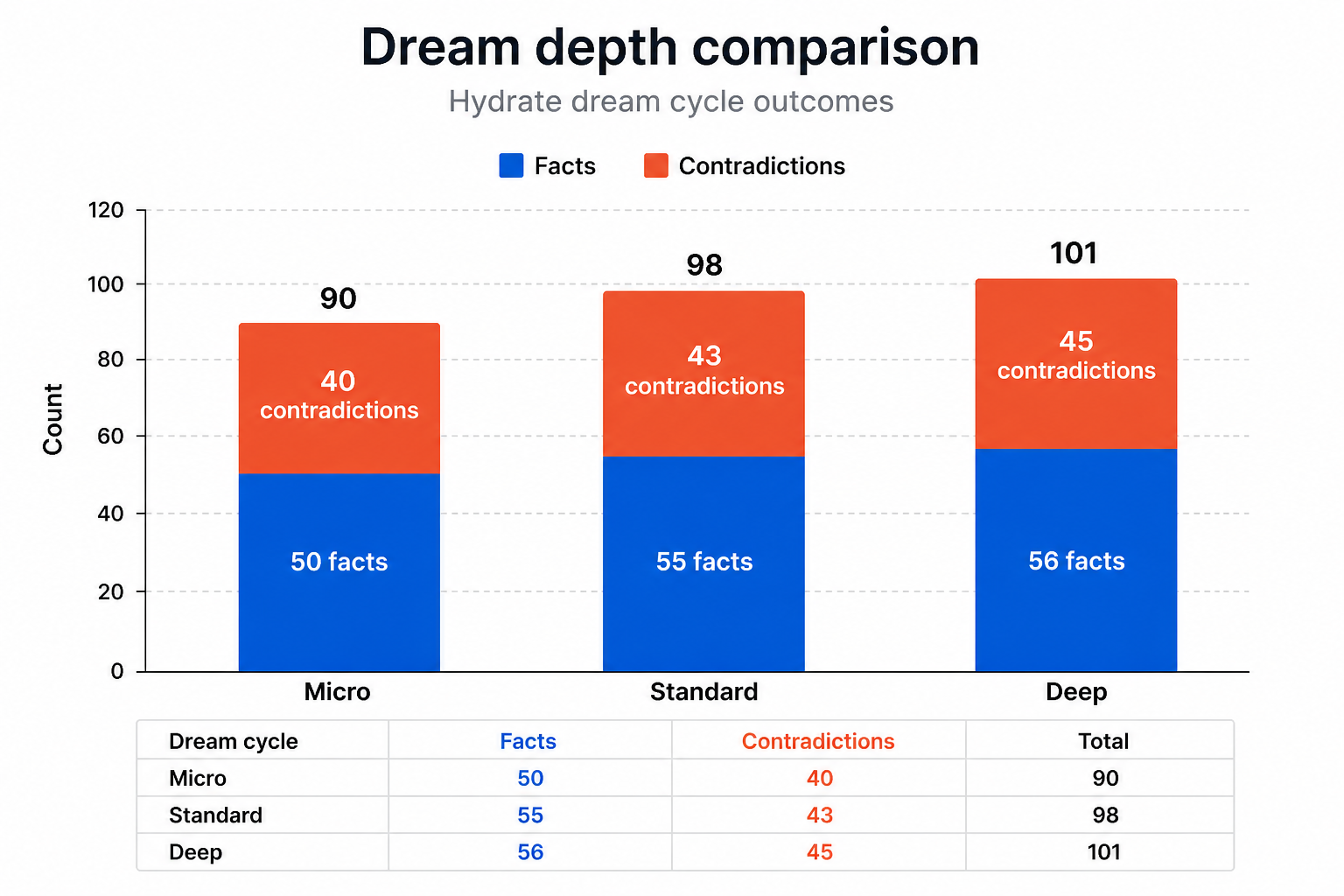
To test whether the three depths actually behave differently, we seeded controlled data: six high-strength facts to push the pool past micro's budget cap, two contradicting medium-strength facts sitting just below micro's 0.3 threshold, and one weak fact at 0.05 that only deep would reach.
The results:
| Cycle | Inputs considered | Contradictions detected |
|---|---|---|
micro | 50 | 40 |
standard | 55 | 43 |
deep | 56 | 45 |
Every number is different. Micro hit its budget cap exactly. Standard reached the medium-strength contradicting pair that micro couldn't see, and its contradiction count rose accordingly. Deep found the 0.05-strength fact and surfaced three additional contradictions that standard missed entirely.
What does this tell you? It tells you that contradiction in a real fact store is not a corner case. It accumulates. Facts written in different sessions, under different mental models, about preferences that have evolved, naturally diverge. The dream system's job is to find that divergence before it surfaces as an unhelpful response.
And the depth you choose matters. Micro is appropriate for frequent, lightweight consolidation: run it at the end of every session automatically and you keep the active corpus reasonably clean. Standard is the right default for a deliberate review. Deep is the one you run periodically, when you want the full picture, including the faded decisions.
The inner monologue
Dreaming is the offline half of the system. The inner monologue is the wake-mode counterpart: it runs during a session, not between them.
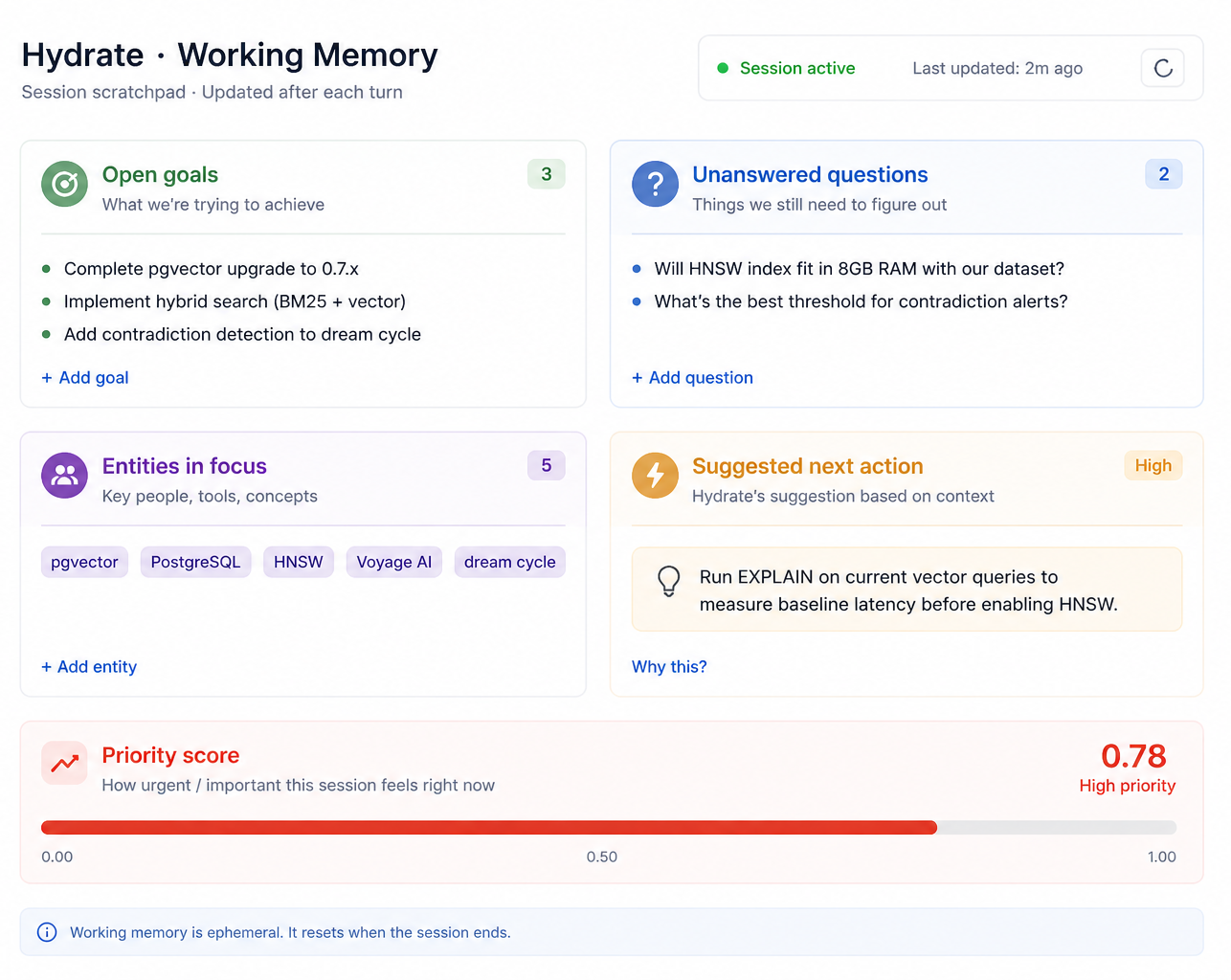
After each turn in a conversation, the monologue engine reads the user's message and the assistant's response. It maintains a lightweight working memory: goals the user has stated, questions that were asked but not answered, entities being discussed, and a measure of how much the assistant hedged in its last response.
The engine runs seven rules against this state. If you asked a question two turns ago and it hasn't been answered, the monologue flags it. If you've restated the same goal four times without resolution, it flags that too, and at higher priority. If the assistant's response was full of hedging language and your query was short, it suggests asking for clarification. If you've circled back to a topic after a gap of four turns, it offers to bring the earlier context forward.
None of this involves a language model either. The rules are pure functions over working memory. They run in under a millisecond per turn.
The output is a stream of suggestions, each with a priority score from 1 to 10. The dashboard shows you everything the monologue considered, including the suggestions it held back. In production, only suggestions with a priority of 7 or above surface to the user. Below that, they're logged and fed into the dream system as seeds.
How they connect
The inner monologue and the dream system are not independent features. They form a loop.
During a session, the monologue tracks uncertainty spikes, unresolved goals, and unanswered questions. These become dream seeds: signals to the offline consolidation cycle about what deserves attention. When the session ends and a dream cycle runs, those seeds influence which contradictions get surfaced in the report.
The working memory the monologue maintains persists across sessions. When you start a new
conversation, calling hydrate_working_memory gives you what the last session
left behind: what you were trying to do, what questions were open, which entities you were
paying attention to. That's the bridge. The monologue keeps it alive.
How a user actually uses this
The MCP tools are the primary interface from Claude Code.
At the end of a session, hydrate_dream_trigger with
cycle_type: "micro" runs a quick consolidation. You'll get back a report:
tone, shape, a contradiction count. If the contradiction count is high, run
hydrate_dream_reports to read what was found. The reports tell you whether
your fact store is clean or drifting.
At the start of a new session, hydrate_working_memory
shows you the carry-forward state from the previous session: what goals were open, what
questions weren't answered, which entities the monologue was tracking. It's an orientation
tool. A session that starts with this context doesn't start from zero.
Periodically, run a deep cycle. Not after every session.
Maybe once a week, or after a significant phase of work. The deep scan reaches fading
facts that haven't been in a context window for weeks. The contradictions it finds are the
ones that have been quietly accumulating since you changed your mind about something three
months ago.
The dream dashboard, available at localhost:49849/dashboard/dreams.html when
hydrate-server is running, shows the full history: cycle runs, report timelines, the
clarity decay from [FUZZY] to [VAGUE]. You can trigger cycles
from the UI and read reports there if the MCP tools aren't in your workflow.
This is not just a Claude Code feature
The maintenance loop belongs to the memory layer, not to one editor. The same working memory, dream reports, and contradiction checks sit underneath Claude Code, Copilot, MCP tools, and future clients. A contradiction flagged during a Claude Code session shows up in the same dream report whether you check it from the dashboard, from Claude Code, or from a Copilot session the next morning. The loop runs once. Every surface benefits.
What this is trying to be
There's a version of AI memory that treats capture as the hard problem and everything else as solved. Record the facts, embed them, retrieve the closest ones. Done.
That version works well enough for simple cases. But real work generates facts across weeks and sessions and changing contexts. Preferences get revised. Architectural decisions get revisited. What was true in session 3 can quietly conflict with what's being said in session 30.
The dream system doesn't try to resolve those contradictions for you. It finds them, surfaces them, and fades them away over 72 hours if you don't act on them. The monologue doesn't try to manage your session for you. It tracks what seems to matter and offers to bring things forward.
Both are designed to stay out of the way. The suggestions are optional. The reports are transient. What the system is doing, while you're not looking, is the kind of quiet maintenance that makes the things you do look more reliable.
That's what consolidation means. Not that the memory is bigger. That it's better.
Try it
- Run a micro dream cycle after your next long session:
hydrate_dream_triggerwithcycle_type: "micro". - Start the next session with
hydrate_working_memoryto see what carried forward. - Check the dashboard at
localhost:49849/dashboard/dreams.htmlto read the full report history.